 ben's notes
ben's notesDynamic Programming
What is Dynamic Programming? #
Dynamic Programming (DP) is a general approach to many types of problems.
Main idea: Solve a big problem by breaking it into smaller subproblems, and solve subproblems in order from small to large.
The Approach:
- Define subproblems (that are smaller than the original problem).
- Show how we can solve the original problem given the answers to the subproblems.
- Define base cases (when to return a simple result).
- Choose the order to solve subproblems such that we can make the algorithm efficient.
How is this different from recursion though? #
- In DP, we solve smaller subproblems first. In recursion, we don’t reach these subproblems until we try to calculate the larger problem.
- In other words, when we reach a larger subproblem, all its subproblems must already have been computed.
Some Examples #
Shortest Paths in DAGs #
The Problem: Given a graph $G(V,E)$ with integer weights (negative weights ok), find the shortest path from $s \in V$ to $v \in V$.
DP Approach:
- Define Subproblems: Find the shortest path from $v'$ to $v$ such that $v'$ is closer to $v$ than $s$.
- Show how to solve the problem given solutions to the subproblems: We can define
dist(v)as equal tomin(dist(u) + w(u, v)for all $(u,v) \in E$. - Define base case(s): The distance is 0 if we’re at $s$, and infinity if $w$ is a source.
- Choose order to solve subproblems: topologically sort vertices starting at $s$.
Longest Increasing Subsequence (LIS) #
The Problem: Given $n$ unsorted numbers $x_1, \cdots, x_n$, find the LIS. For example, in $1, 3, 2, 7, 4, 5, 6$, the LIS would be $1,3,4,5,6$.
We can reframe this problem to finding the longest path in a DAG
DP Approach:
- Define Subproblems: Find the LIS for a subset $x_1, \cdots, x_i$.
- Solve using subproblems: $L(i) = max(1, max(L(j) + 1))$ for all $x_j < x_i, j
- Base case: $L(1) = 1$. The LIS of a single number is the number itself.
- Order to solve: Pick increasing $i$.
Edit Distance #
The Problem: How similar are 2 strings (character lists $[x_1, \cdots x_n]$ and $[y_1, \cdots, y_m]$)? More specifically, how many edits are needed to change $x$ into $y$?
- An edit is either an insertion, deletion, or substitution of a single character.
This is an important problem for spellchecking, autosuggestions, spam filtering, DNA matching, …
DP Approach:
Define Subproblems: for all length $i$ subsequences of $x$ and all length $j$ subsequences of $y$, we can compute $f(i, j) := ED([x_1, \cdots, x_i], [y_1, \cdots, y_j])$.
Solve using subproblems: Look at the last character in the optimal alignment, and do one of three things:
- Remove $x_i$: will cost $f(i-1, j) + 1$.
- Insert $y_j$: will cost $f(i, j-1) + 1$.
- Replace $x_i$ with $y_j$: will cost $f(i-1, j-1)$ + $\Delta(i,j)$ where $\Delta(i,j)$ is 0 if $x_i = y_j$, and 1 if $x_i \ne y_j$.
The edit distance is thus the minimum of the three above choices.
Base Cases: $f(i, 0) = i$ (deletions), $f(0, j) = j$ (inserts).
Order to solve: The goal is to go from the top left corner in the diagram below to the bottom right corner. Some more details:
- The first row and first column can automatically be filled in (with the base cases).
- Going right is equivalent to inserting a character; going down is equivalent to deleting a character.
- At a particular box, we can either go right (insert), down (delete), or diagonal (replace). We’ll take the path that minimizes the length of the path.
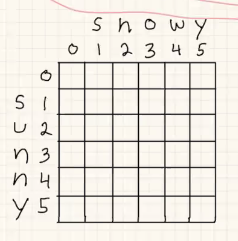
This algorithm will cost $O(m \cdot n)$ time and $O(\min(m, n))$ space. Again, we can think about this like a shortest path in a DAG where each vertex is a possible edit, and each edge weight is the cost of that operation.
To do this more efficiently when the number of expected edits is less than the length of the string: Smith-Waterman algorithm
Knapsack Problem #
Problem: Suppose we have a knapsack that can carry $w$ pounds and we have to choose between $n$ items each with values $v_1, \cdots, v_n$ and weights $w_1, \cdots, w_n$.
We need to pick a subset of items such that we maximize the values while still staying under the maximum weight allowed.
DP Solution:
- Subproblems: Let $f(i, u)$ be the maximum value of packing a subset of $1, \cdots, i$ with a max weight $u \le W$.
- Solve using subproblems: If $w_i > u$, it’s too heavy and we should try $f(i-1, u)$. Otherwise, we could possibly pack $w_i$ and so we should get the maximum value between $f(i-1, u)$ and $v_i + f(i-1, u-w_i)$.
- Base Case: $f(0, u) = 0$ (out of items), $f(i, 0) = 0$ (out of weight capacity)
- Order: For $i$ from 1 to $n$ and $u$ from $1$ to $w$, calculate
max(f(i-1, u), f(i-1, u-w_i) + v_i).
This algorithm is NP-complete and can be computed in $O(n \cdot W)$.
Knapsack with Repetition #
Now, let’s consider a knapsack problem where it’s OK to choose an item multiple times.
The main difference is that subproblems now cannot reduce the number of items in the set, only the weight.
DP Solution:
- Subproblems: Let $K(w)$ be the max value we can get with a weight capacity at most $w$.
- Solve using subproblems: $K(w)$ can be computed using the maximum of $K(w - w_i) + v_i$ for all items $i$.
- Base case: $K(0) = 0$: if we have no capacity, there is nothing more we can store.
- Order: We can solve in increasing order of weight $w$.
This algorithm takes $O(n \cdot W)$ because every evaluation of $K(w)$ requires iterating through the entire list of weights. We do this $W$ number of times (one for each possible max weight).
Chain Matrix Multiplication #
We’ve seen how naively multiplying an $x \times y$ matrix and a $y \times z$ matrix takes $xyz$ number of operations.
Now, supposing we have a chain of matrices to multiply $A_1, A_2, \cdots A_n$. We can use dynamic programming to multiply as cheaply as possible.
One thing to notice is that the order matters: every multiplication changes the dimension of the current result, and having the smallest dimensions possible will reduce the number of operations needed.
For example, if $A_1$ is 50x1, $A_2$ is 1x50, and $A_3$ is 50x1, the result of multiplying $A_1 A_2 A_3$ will have dimension 50x1. If we multiply $(A_1 A_2) A_3$, then it will take $50 \times 1 \times 50 = 2500$ operations. However, if we multiply $A_1 (A_2 A_3)$, then it will take $1 \times 50 \times 1 = 50$ operations, which is 50x better!
Let’s try to find an algorithm to group the matrices together to get this smallest possible runtime.
DP Solution:
- Subproblems: Let $C(i,k)$ be the optimal cost for multiplying a subsequence $M_i, \cdots M_k$.
- Recurrence: We can compute $C(i, k)$ by taking the minimum of $C(i, j) + C(j, k) + M_i M_j M_k$ for every $i < j < k$.
- Base case: If we have a single matrix (i.e. $k-1 = 1$), then there is no more work to be done. There are actually $n$ base cases for this problem.
- Order: Find $C(0, n)$.
Runtime: There are $O(n^2)$ number of subproblems to solve ($1+2+3+\cdots+n$), and each one takes $O(n)$ time to solve since we need to do the $M_i M_j M_k$ operation for every $j$. Together, this means that the algorithm requires $O(n^3)$ time to run.
All-Pairs Shortest Paths #
Given a graph $G(V,E)$ with weighted integer edges, find the distance from vertex $u$ to vertex $v$ for every $u,v \in V$.
A naive algorithm is to run Bellman-Ford on every possible source, taking $O(|V| \cdot |V| \cdot |E|)$ time.
We can reduce this using dynamic programming and the Floyd-Warshall Algorithm.
DP Solution:
- Subproblems: Let $d(u, v, i)$ be the shortest path from $u$ to $v$ using only the first $i$ vertices in the intermediate path.
- Recurrence: We can solve $d(u, v, i)$ by taking the minimum of $d(u, v, i-1)$ (vertex $i$ is not part of the shortest path), or $d(u, i, i-1) + d(i, v, i-1)$ ($i$ is in the path and so we include the edge from $u$ to $i$ and find the remaining path to $v$ from $i$).
- Base case: $d(u, v, 0)$ can result in one of two simple cases:
- If $(u,v)$ is an edge, then the shortest path is the length of that edge.
- If $(u,v)$ is not an edge, then there is no shortest path from $u$ to $v$ with no intermediate vertices.
- Order: Compute all $d(u,v,i)$ starting from $i=0$ and going up to $i=|V|$. Repeat this for every pair $(u,v)$ at each $i$ before incrementing it.
If we already computed the subproblems, then solving $d(u,v,i)$ takes constant time. We know that there are $O(|V|^3)$ number of subproblems because we can vary the values of $u,v,i$ independent from one another, and all have a max value of $|V|$. If we calculate using the order specified above, then we will never need to calculate a subproblem more than once.
Traveling Salesperson Problem #
Given a graph $G(V,E)$ with integer edge weights, output a shortest tour (cycle visiting each vertex once) of $G$.
As a naive approach, we can simply compare all possible tours. There are $(n-1)!$ number of tours, and each tour takes $O(n)$ time to evaluate, where $n$ is the number of vertices to visit, so overall it takes $O(n!)$ time to use this method.
DP Solution:
- Subproblem: Let $C(S, j)$ be the shortest path from 1 to $j$ visiting each vertex in $S$ once. We will assume that $1,j \in S$.
- Recurrence: We can evaluate $C(S,j)$ by trying every possible set $C$ containing $1,j$ for every $j$. So, $C(S, j) = \min(C(S - \{i\},i) + l(j,1)$ for $i \in S, i \ne j$.
- Base cases: $C(\{1\}, 1)$ is trivial (path from 1 to itself is 0 length), $C(S ,1)$ means there is no path if $|S| > 1$ (since we can’t visit every vertex once, 1 is visited twice).
- Order:
Runtime: There are $2^n$ possible subsets $C$, and we need to evaluate each subset for every possible $j$. So, there are $O(2^n \cdot n)$ number of entries.
Each entry takes $O(n)$ time to compute since we need to iterate through $n$ number of other entries and take the min, so overall this algorithm takes $O(2^n \cdot n^2)$ time to run.