 ben's notes
ben's notesHuffman Coding
The Problem: Data Compression #
Given a string of characters ABACCDBB... from an alphabet $\{A,B,C,D \cdots\}$, how may bits do we need in order to encode it?
Of course, there is the naive way (just store the entire string), which requires $O(n)$ bits, but with Huffman encoding, we can do better!
Prefix-Free Codes #
One strategy is a greedy algorithm which assigns more frequently seen characters a shorter length bit representation. For example, if A occurs 40% of the time, B 30%, C 20%, and D 10%, we could do something like:
A → 0, B → 10, C → 110, D → 111
On first glance, that doesn’t seem to be any improvement (since C and D now use 3 rather than 2 bits). However, we can calculate the total improvement:
$.4n \cdot 1 + .3n \cdot 2 + .2n \cdot 3 + .1n \cdot 3 = 1.9n$, a slight improvement over the original $2n$.
Prefix-Free Codes and Trees #
A prefix free code is a bit representation of an alphabet such that no character is a prefix for another. For instance, A -> 0, B -> 1 is a prefix-free code; A -> 0, B -> 01 is not since A is a prefix of B.
There is a 1 to 1 correspondence between prefix free codes and full binary trees, where each character is a leaf, left branches are 0, and right branches are 1.
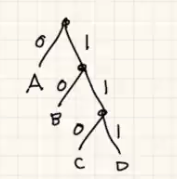
If we would like to use prefix-free codes, then we can find the full binary tree that minimizes the cost $\sum f_i \cdot len(i)$ for each $i$ in the alphabet where $f_i$ is the frequency and $len(i)$ is the length of the bit representation.
It seems intuitive that the least frequent letter should take the most bits, and therefore be at the bottom of the tree. We can formalize this into an algorithm and make a proof:
Claim: Suppose we have frequencies $f_1 \le f_2 \cdots f_n$. Then, $f_1$ and $f_2$ must be siblings at the bottom of the tree.
Proof: We can prove this by contradiction. Suppose that $f_1$ and $f_2$ are actually not at the bottom of the tree.
In this case, if we swap $f_1$ and $f_a$ (a value at the bottom) and $f_2$ with $f_b$, the cost is guaranteed to be lowered because $f_1 \le f_a$ and $f_2 \le f_b$. Putting a larger frequency at a lower length and a smaller frequency at a longer length must reduce the cost.
If we apply this claim repeatedly to all $f_1, \cdots f_n$, we can see that:
- The length of
f_3is equal to the sum of the lengths of $f_1$ and $f_2$. - The length of
f_4is equal to the sum of the lengths of $f_1$, $f_2$, and $f_3$. - …And so on: the length of $f_i$ is the sum of the lengths of all characters less frequent than it.
Greedy Algorithm for Optimal Tree #
Here’s how we actually construct the tree described above:
- Pick the 2 least frequent characters.
- Replace the 2 characters with 1 character with frequency $f_1 + f_2$.
- Recursively find the optimal tree with $n-1$ characters.
- Replace the leaf for $f_1+f_2$ with $f_1, f_2$.
Proof: This tree is optimal (gives lowest lengths possible).
We can prove this with induction on $n$ (the number of characters):
Base Case: if there are either 1 or 2 characters, then just use 1 bit so the tree is optimal.
Recursive case: Let $T'$ be a tree on $f_1+f_2, f_3, \cdots f_n$ which is optimal by the inductive hypothesis. Now, if we construct $T = f_1, f_2, \cdots f_n$ by replacing $f_1 + f_2$, then the cost will be the same (since we’re simply splitting $f_1+f_2$, and their lengths are still the same).
If $T'$ was optimal, then by extension $T$ must be optimal as well, which satisfies the inductive hypothesis.
Code for Constructing the Optimal Tree #

O(n * cost(deletemin) + n cost(insert)) = O(nlogn)
Entropy #
What is information? #
The amount of information $I(p)$ known from the outcome of a random event with probability $p$ is:
- 1 bit if $p = 0.5$ (intuitively, since two outcomes are equally likely).
- More than 1 bit if $p < 0.5$:
- For example, if we flip 2 fair coins, and they both come up heads, $p = 0.25$. We need 2 bits to store this information (1 for each coin).
- More formally, $I(p_1 \cdot p_2)$ = $I(p_1) + I(p_2)$.
We can satisfy these properties of information using the log function:
$I(p) = \log_2(\frac{1}{p})$
Information and Entropy #
Suppose we have $n$ possible outcomes, each with probability $p_1, p_2, \cdots p_n$.
The expected information $E(I)$ is then the sum $\sum p_i \log_2(\frac{1}{p_i})$ over all $i$ from 1 to n.
Entropy measure how “random” a distribution is, ranging from $0$ (know the result with absolute certainty) to $\log_2(n)$ (all outcomes are equally likely).
Entropy and Huffman Coding #
In Huffman coding, suppose all $f_i = p_i = \frac{1}{2^{k_i}}$ where the depth of $f_i$ is saved in the value $k_i$.
Encoding $m$ characters with frequencies $p_i$ takes $m \cdot \sum p_i \cdot len(f_i)$ which is equal to $m \cdot E(I)$. This is known as the Shannon Entropy, which is a lower bound for how efficient a particular encoding scheme can be (i.e. length of tree = entropy).