 ben's notes
ben's notesSorting
General Introduction #
The problem of sorting: given a list of numbers $a_1, \cdots, a_n$, output them in increasing or decreasing order.
The Idea (Divide and conquer):
- Split the list in to two halves.
- Recursively sort each half.
- Merge the two halves together.
This sounds familiar…
Merge Sort #
def mergesort(lst):
if lst has 1 element:
return lst[0]
s_l = mergesort(first half of lst)
s_r = mergesort(second half of lst)
s = merge(s_l, s_r)
return s
def merge(s_l, s_r):
result = []
while s_r is not empty:
if s_l is empty:
return result + s_r
if s_l[0] > s[r]:
result += s_l[0]
remove s_l[0]
return result + s_l
The runtime of the merge operation is $\Theta(|s_l| + |s_r|)$ since we go through each element in each list exactly once.
The total runtime of the mergesort algorithm is the recursive relation $T(n) = 2T(n/2) + O(n)$ (splits into 2 subproblems, which are balanced, and add on the runtime of merging).
By the Master Theorem of Recurrences, $a=2,b=2,d=1$ so $\frac{a}{b^d}$ = $\frac{2}{2}$ = 1. This tree is balanced so the runtime is $O(n^d\log_b(n)) = O(n\log(n))$.
Mergesort is a type of comparison sort: which is a sort in which the only operation performed on the inputs are comparisons (e.g. no adding, etc).
💡 Theorem: Any comparison sorting algorithm requires $\Omega(n\log(n))$ comparisons to sort a list of $n$ elements. Therefore, mergesort is optimal among comparison sorts.
Proof of Theorem:
Suppose we have a comparison sorting algorithm $A$ and a list $a_1, \cdots, a_n$. The computation of $A$ on the list defines a permutation $\pi: [n] \to [n]: a_{\pi(1)}, \cdots, a_{\pi(n)}$.
Let $S$ denote the set of possible permutations at a given point in time during the running of $A$.
At the initial state, there are $n!$ possible permutations out of $n$ items.
When $A$ makes a comparison, one of two results occur (based on the comparison made). In one result, one permutation is outputted; in the other, another permutation is outputted.
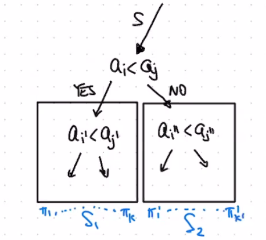
Since $S_1 \cup S_2 = S$, either $S_1$ or $S_2$ must be at least as large as half of $S$. So, in the best case, the set of all possible permutation halves for a single comparison.
Since we keep going until the size of $S$ is $1$ (base case), we can figure out how many layers (comparisons) are required before $S$ can be reduced to the base case. Since we start with $n!$ permutations, and the number halves each layer, there are $\log(n!)$ number of layers.
The best case scenario is when the size exactly halves, so:
$c \ge \log_2(n!) \ge \log_2((\frac{n}{e})^n) = n\log(n) - n\log(e) = \Omega(n\log(n))$.