 ben's notes
ben's notesUtilities and Decision Trees
Utility #
Utilities are values that determine the relative benefit of a particular state: the higher the utility, the better. For the statistical-decision-theory perspective on the same idea (loss functions, estimators, Bayes vs. minimax risk), see decision theory.
Rational agents follow the principle of maximum expected utility (MEU): they always choose whichever actions maximize expected utility. Rational agents must also have rational preferences and therefore follow the axioms of rationality:
- Orderability: $(A>B) \lor (B>A) \lor (A \sim B)$
- Rational agent either prefers A or B, or is indifferent
- Transitivity: $(A > B) \lor (B > C) \implies (A > C)$
- If rational agent prefers A over B and B over C, then it prefers A over C.
- Continuity: $(A > B > C) \implies \exists p [p, A; (1-p), C] \sim B$
- If rational agent prefers A over B and B over C, then it’s possible to choose a probability $p$ such that the agent is indifferent to running a lottery of $A$ and $C$ vs. choosing $B$.
- Substitutability: $(A \sim B) \implies [p, A; (1-p), C] \sim [p, B; (1-p), C]$
- If rational agent is indifferent between $A$ and $B$, it is also indifferent between two lotteries that are identical except $A$ is substituted with $B$
- Monotonicity: $(A > B) \implies (p \ge q \iff [p, A; (1-p), B] \ge [q, A; (1-q), B])$
- If rational agent prefers $A$ over $B$, then between two lotteries involving $A$ and $B$ it will choose the one that assigns a higher probability for $A$
Risk-neutral agents are indifferent in participating in a lottery over choosing a guaranteed action.
Risk-averse agents prefer a guaranteed action.
Risk-seeking agents prefer a lottery.
Maximum Expected Utility Equations #
- No evidence: $MEU(\emptyset) = \max_a EU(A=a) = \max_a \sum_s P(r_a = s) U(S)$
- Given evidence: $MEU(E=e) = \max_a EU(A=a|E=e) = \max_a \sum_s P(r_a = s | E = e)U(s)$
- Hidden evidence: $MEU(e) = \sum_eP(E=e)MEU(E=e) = \sum_e P(E=e) \max_a \sum_s P(r_a = s | E = e)U(s)$
- Hidden and given evidence: $MEU(E=e, E') = \sum_e' P(E' = e'|E=e)\max_a \sum_s P(r_a = s | E = e, E' = e')U(s)$
Decision Networks #
Decision networks are a combination of Bayes nets with expectimax trees. They have three main types of nodes:
- Chance nodes work in the same way as Bayes nets nodes: each chance node has a probability table detailing its outcomes. (Ovals)
- Action nodes represent a choice between actions in which we have control over. (Rectangles)
- Utility nodes output a utility based on the values in their parents. (Diamonds)
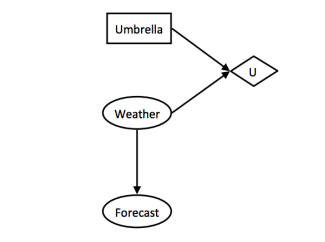
The maximum expected utility (MEU) can be calculated using the following procedure:
- Instantiate all known evidence.
- Run inference to calculate probabilities of all chance nodes that are fed by the current action.
- For each action, compute the expected utility given posterior probabilities (calculated in step 2) using the following formula:
- $EU(a|e) = \sum P(x_1, \cdots, x_n | e) \times U(a, x_1, \cdots, x_n)$ where $a$ is the action being taken, $e$ is the evidence, $x_1, \cdots, x_n$ are chance nodes
- i.e. sum over all possible states $s$ corresponding to a particular result that can be achieved by a chosen action $a$
- Choose the action with the highest expected utility.
Value of Perfect Information (VPI) #
VPI mathematically quantifies the expected increase of an agent’s MEU given that it observes a new set of evidence. This can be used to determine how useful it is to seek out the evidence (since observation often comes at a cost).
We know that the current maximum utility given evidence $e$ is $MEU(e) = \max_a \sum_s P(s|e) U(s, a)$.
If we include new evidence (represented by the random variable $E’$), then
$MEU(e, E’) = \sum_{e’} P(e’ | e) MEU(e, e’)$
Thus, we can measure VPI using the following formula:
$VPI(E’|e) = MEU(e, E’) - MEU(e)$
VPI has the following properties:
- Nonnegativity: observing new information always makes MEU either stay the same or increase.
- $VPI \ge 0$. If evidence is independent of the utility function, then VPI is guaranteed to be $0$.
- Nonadditivity: the VPI of observing two different pieces of evidence individually is not equal to the sum of observing both of them together
- Order-independence: observing multiple evidences yield the same gain in MEU regardless of the order we observe them
It is always possible for VPI to be equal to $0$ (if the evidence is independent of the measured state).