 ben's notes
ben's notesHashing and Hash Tables
Data Indexed Sets: Introduction #
So far, we’ve explored a whole bunch of ways we can store items, but they aren’t really optimized for general searching. What if we could get searching in $\Theta(1)$ time??? Wouldn’t that be nice!
See also: 04 Sorting and Hashing (external hashing for databases that don’t fit in memory), hashing-and-the-union-bound (the probability of collisions and the birthday problem), and Cryptography (cryptographic hash functions used for integrity).
Let’s try something: putting all of our data in a massive array. Let’s say that we know all our data falls into the range from 0 to 10,000 and make an array of 10,000 length to hold stuff.
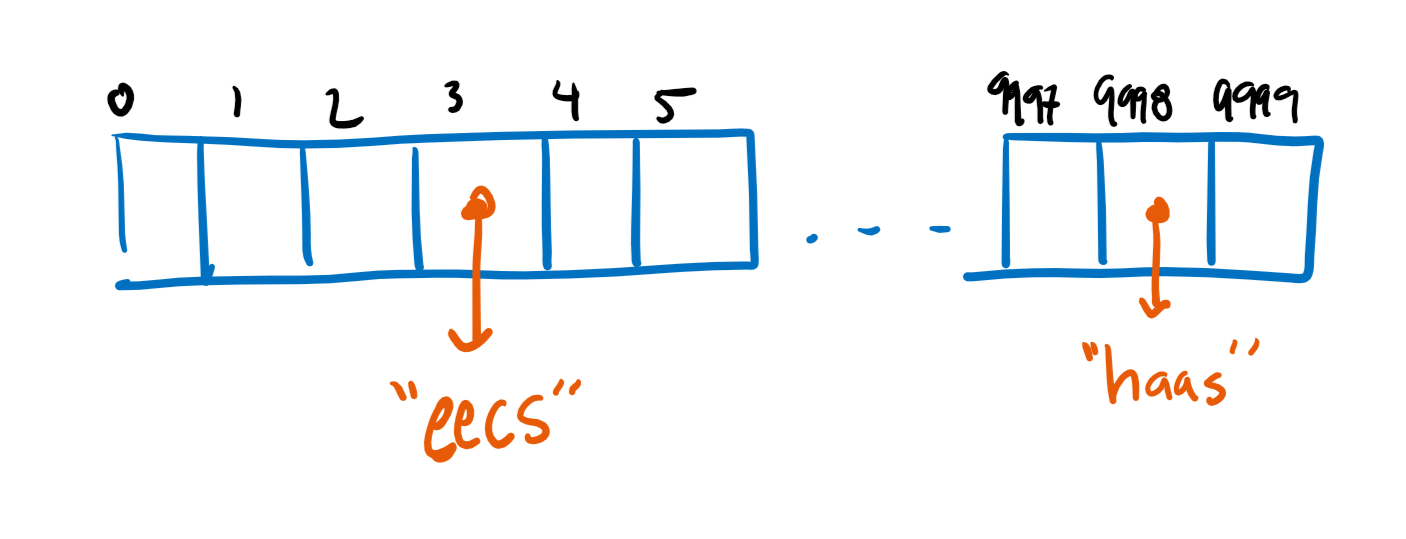
Here, it doesn’t matter what index each item is stored in- if we want to get “eecs” which is stored at key 3, it will be as instantly accessible as “haas” which is all the way in 9998.
Of course, this has a major design flaw that you can probably see right away. It takes way too much memory!
Hash Codes #
Let’s figure out a way to get around the issue of space, but still not lose our awesome constant-time property. One way we can do this is to represent each item with a hash code and store them into the index with that hash code.
For instance, let’s use the first letter of a word as the hash code. We have just turned a nearly infinite space of possibilities into something that can be stored in just 26 buckets.

While this solution is great, it still has another major drawback, which can be illustrated with this example:
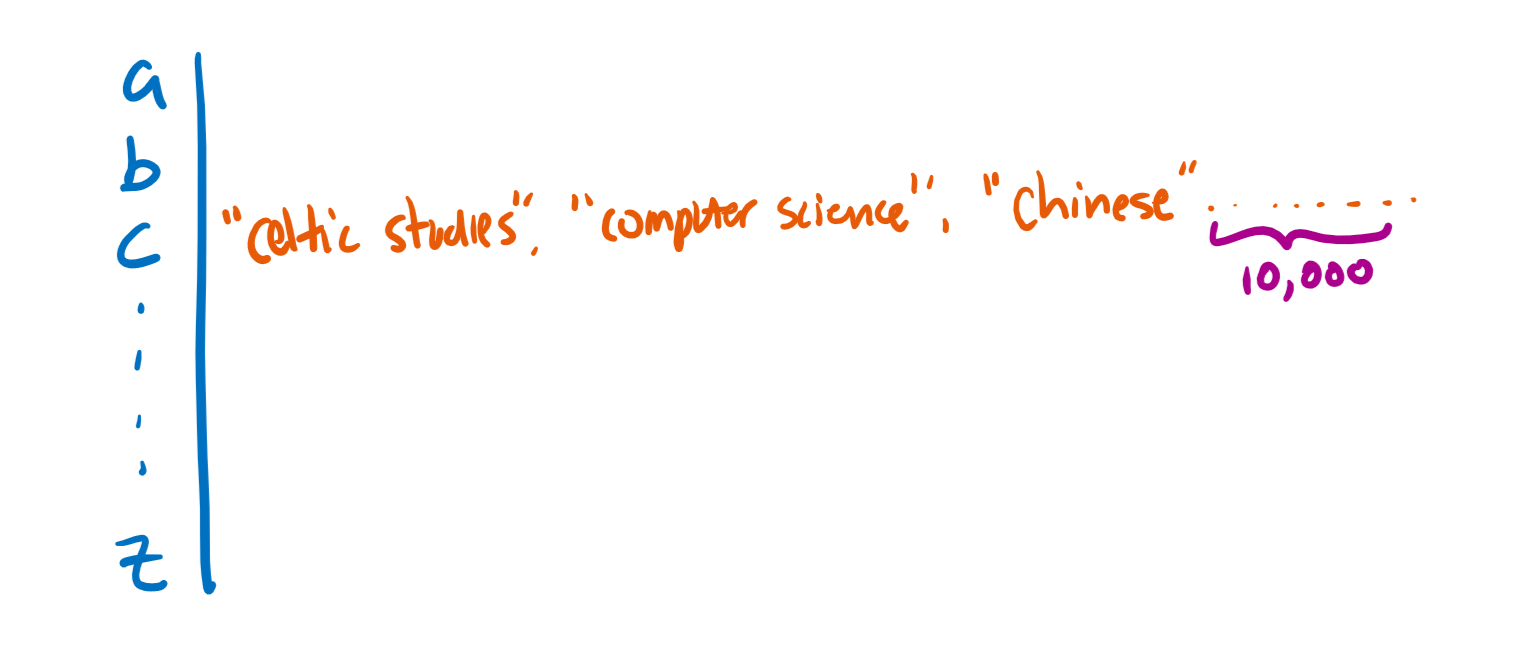
In the worst case, this just turns back into a linked list! That means the runtime just went from O(1) to O(n), and that’s no good.
Good Hash Codes #
If we can somehow create a “good” hash code, we can prevent things like the example above from happening because there shouldn’t be a clear pattern in what buckets different objects go to. More specifically, a good hash code:
- Ensures that two objects that are equal have the same hash code.
- Ensures that no distinguishable pattern can be made out of hash codes from different objects.
- Returns a wide variety of hash codes (not just putting everything into a single bucket, for example).
Luckily, Java already handles hash code generation for us using the hashCode() function in the Object class. This function returns an integer that can be used to create good hash tables.
Dynamic Resizing #
Let’s add another feature to our hash table: dynamic resizing. This means that the number of buckets will increase proportionally to the number of items in the set.
One fairly simple way to do this with a numerical hash code is to mod the hash code by the number of buckets to get which bucket an item is stored in. For example, if an item has hash code 129382981 and we have 10 buckets, then we put it in bucket 1, or 129382981 % 10.
In order to do this, we’ll choose a load ratio at which to resize. This load ratio is calculated as N/M, where N is the number of items and M is the number of buckets. For example, a load ratio of 2 will mean the table resizes when, on average, each bucket has 2 items in it.
When resizing, we must recompute all the hash codes so that we can balance out all of the buckets again.
This has some cool runtime implications that are closely related to Amortization. Like what happened in the dynamically resizing array, resizing hash tables like this is also a $\Theta(1)$ operation. Nice!
Java Hash Tables #
In Java, hash tables are used in the data structures HashSet and HashMap which are the most popular implementation of sets and maps.
These two implementations provide fantastic performance and don’t require values to be comparable like trees do.
However, they have a drawback that must be considered: objects cannot be modified after they are put into the hash table. This is because mutating an object will change its hash code, which means that the object will be lost forever since its bucket doesn’t match the current hash code!
If the built-in hash code generator isn’t what is needed (like you want two objects to be equal if they have the same size, for instance), you can override the hashCode() method. Be careful when doing this because hashCode() relies on equals() to find which bucket objects are in! So, if hashCode is overridden, it is highly recommended to override equals as well to ensure that they are compatible.