 ben's notes
ben's notesParallelism
Using Parallelism for Performance #
In recent times, the performance improvements with single-threaded performance have been small, and CPU clock rates are no longer increasing. Therefore, we must turn to parallel processing to improve speed.
There are two main ways to do so:
Multiprogramming: Run multiple programs at the same time. This is how multi-core systems work (e.g. use one core for one program, another core for another). This is handled by the OS and is relatively easy to handle.
Parallel Computing: Run a single program more quickly by running multiple instructions at the same time.
SIMD and Flynn’s Taxonomy #
In contrast to SISD (single instruction single datastream), where instructions are processed sequentially, one at a time, SIMD (single instruction multiple datastream) processes multiple data streams using a single instruction stream. In other words, “do A then B then C in order, but do these steps on multiple things at the same time.”
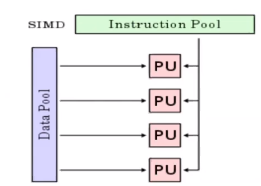
(There is also MIMD (multiple instruction multiple datastream) and MISD (multiple instruction single datastream) but we won’t talk about that for now.)

SIMD and MIMD are the most common examples of parallelism in real-life architecture.
Intel SIMD Intrinsics #
Intel CPUs have special SIMD instructions that apply to 16 parallel registers.
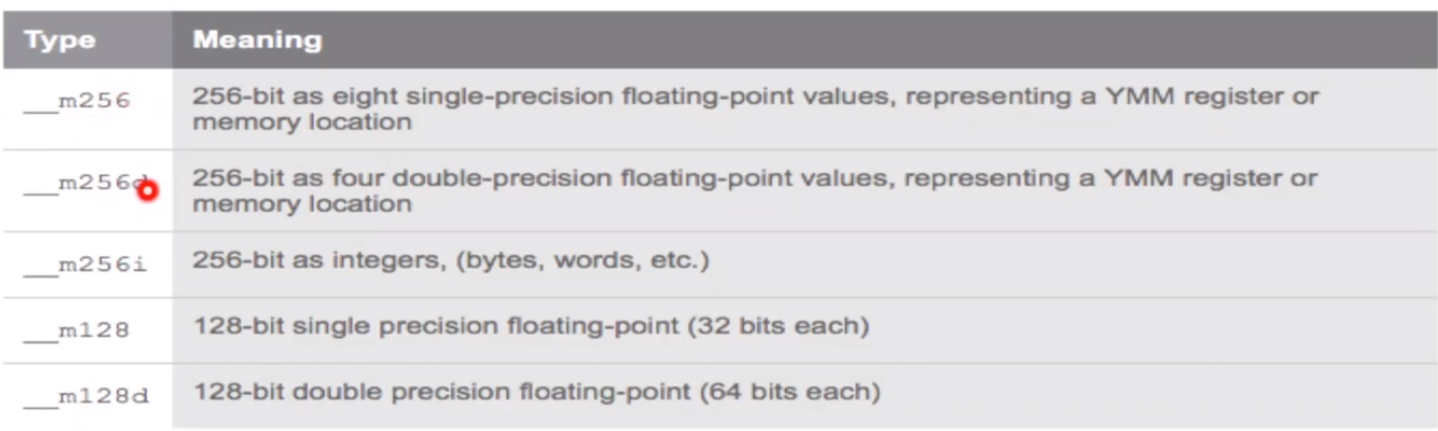
These registers are either 128-bit (in AVX-128) or 256-bit (in AVX-256). The latter can store 8 floats, 4 doubles, 32 bytes, etc.
Intrinsics allow direct access to assembly instructions

Matrix Multiple Example #

- Initialize a 256-bit double precision register to hold 4 zeroes.
- Load four floating point values at the same time from
a+i+k*N, and then load a single value fromb+k+j*N. - Perform the matrix operation sequence for these 4 values and store them all into the block of memory starting at
c+i+j*N, all at the same time.
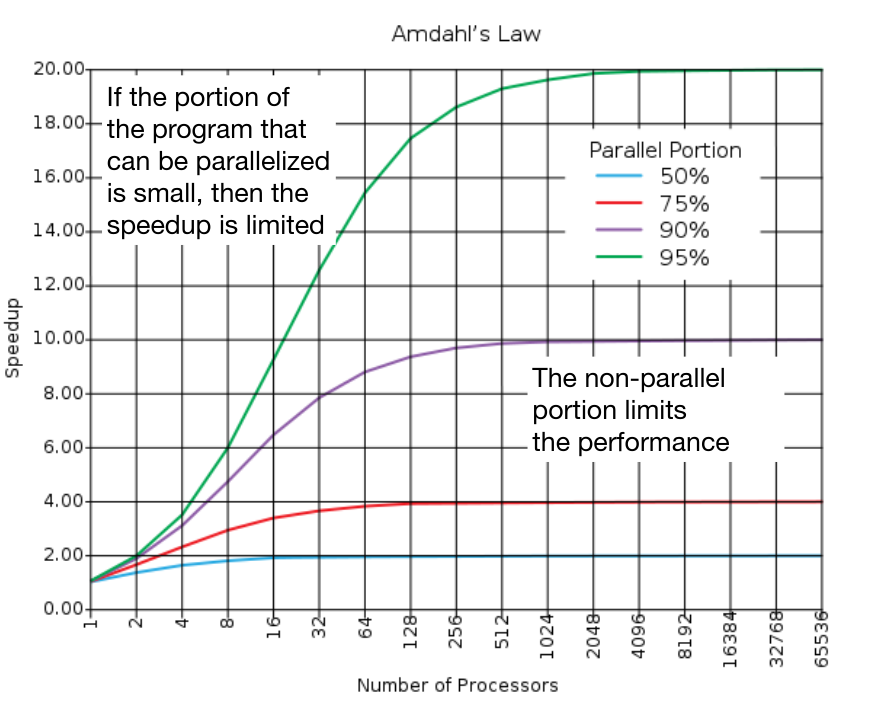
Amdahl’s Law #
The speedup due to an enhancement $E$ is equal to the ratio between execution time without $E$ and execution time with $E$.
Speedup = $\frac{1}{(1-F) + F/S}$ where $E$ accelerates a fraction $F < 1$ of the task by a factor of $S > 1$.
For example, if we can double the speed of executing half the problem, $F = 0.5, S = 2$ and the overall speedup is $1.33$.
One consequence of Amdahl’s law is that in order to achieve a linear speedup with respect to the number of processors, almost none of the original computation can be scalar!
Strong and Weak Scaling #
Strong scaling: when speedup can be achieved on a parallel processor without increasing the size of the problem
Weak scaling: when speedup is achieved by increase the size of the problem proportionally to the number of processor
MIMD Computing #
Now that we have hit a wall in terms of performance for single-stream processing, the only path to further performance is parallelism.
There are two ways to use a multiprocessor:
- Use job-level parallelism to handle independent jobs simultaneously (i.e. OS),
- Improve the runtime of a single parallel-processing program.
MIMD uses threads, which are sequential flows of instructions that perform a task. Each thread has their own registers and accesses shared memory.
If there are multiple cores in the CPU, each core provides hardware threads. OS’s then have to map software threads onto hardware threads.
Since there are usually more software threads than hardware threads, the software threads have to be multiplexed over time to give the illusion of allowing for more threads.
In multithreaded cores, the hardware can switch threads while waiting for cache misses, etc. to reduce idle time.
OpenMP #
OpenMP is a language extension used for multithreaded shared-memory parallelism.
It consists of:
- Compiler directives (in source code)
- Runtime library routines (called from source code)
- Environment variables (set from shell)
OpenMP is a standardized library built on top of C:
- Import using
#include <omp.h> - Compile using
gcc -fopenmp
Some benefits of thread-based parallelism:
- Only have to modify small parts of code (i.e. the bottlenecks)
- Since it uses shared memory, programmers don’t need to worry about data placement.
- Compiler directives are relatively simple.
Some drawbacks:
- Code can only be run in shared memory environments.
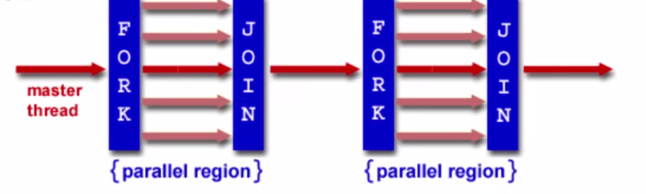
The OpenMP Programming Model #
Fork-Join model: Fork off some threads, then when they all finish, join them all back together and finish the sequential portion of the code.
The basic building blocks of OpenMP are pragmas, which allow preprocessing for language extensions of C.
Compilers that don’t recognize a pragma just ignore them. So if OpenMP code is compiled on a non-multithreaded system, then it acts just like any other program.
As a code example:
omp_set_num_threads(x); // set num threads to x
omp_get_num_threads();
#pragma omp parallel
{ // MUST GO ON NEWLINE!!
// Do code here
omp_get_thread_num();
}
int x = 0;
#pragma omp parallel private(x)
{
x = omp_get_thread_num();
...
}
int i = 0;
#pragma omp parallel // for loop parallel
{
for (i = omp_get_thread_num(); i < num_steps; i+=NUM_THREADS) {
...
}
}
By default, all variables are shared. To make a private variable, use #pragma omp parallel private(x).
One issue is a data race where multiple threads need to access data at the same location, but the one that reads accesses it before the one that writes.
We can avoid these by synchronizing reads and writes. This is done with lock synchronization: a “lock” grants access to a critical section of data so only one thread can operate on it at a time.
- A thread can acquire and release the lock based on when it is done. If it requires a resource that is locked by another thread, then it can idle until the lock is released.
- One potential issue is deadlock: when everything is locked waiting for something else to complete.
Another method of reducing data races is reduction: each thread gets a private variable, then when every thread is done, a reduction operation is called to combine the private variables into the final result. (For example, create an array with one element for each thread. Then, sum the array at the end.)
Multicore Processors #
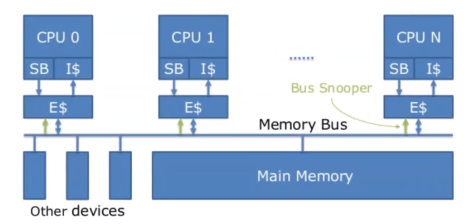
In modern CPUs, multi-core processors have a single, shared address space. Individual processors then communicate through loads and stores of shared variables.
- These shared variables are locked if being accessed by a processor.
- A shared memory bus connects processors to the memory.
This is known as a shared memory multiprocessor.
Cache Coherence #
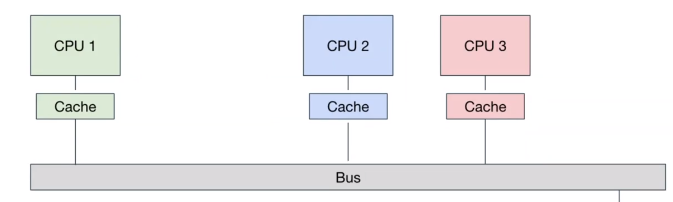
Every CPU has its own cache, so we need the concept of cache coherence to figure out how to make sure the caches all have the same view of main memory (even if a CPU writes).
- writeback caches store edits and only write to main memory if the cache is evicted. This saves on costly memory writes.
- Communication is done with a broadcast to other processors.
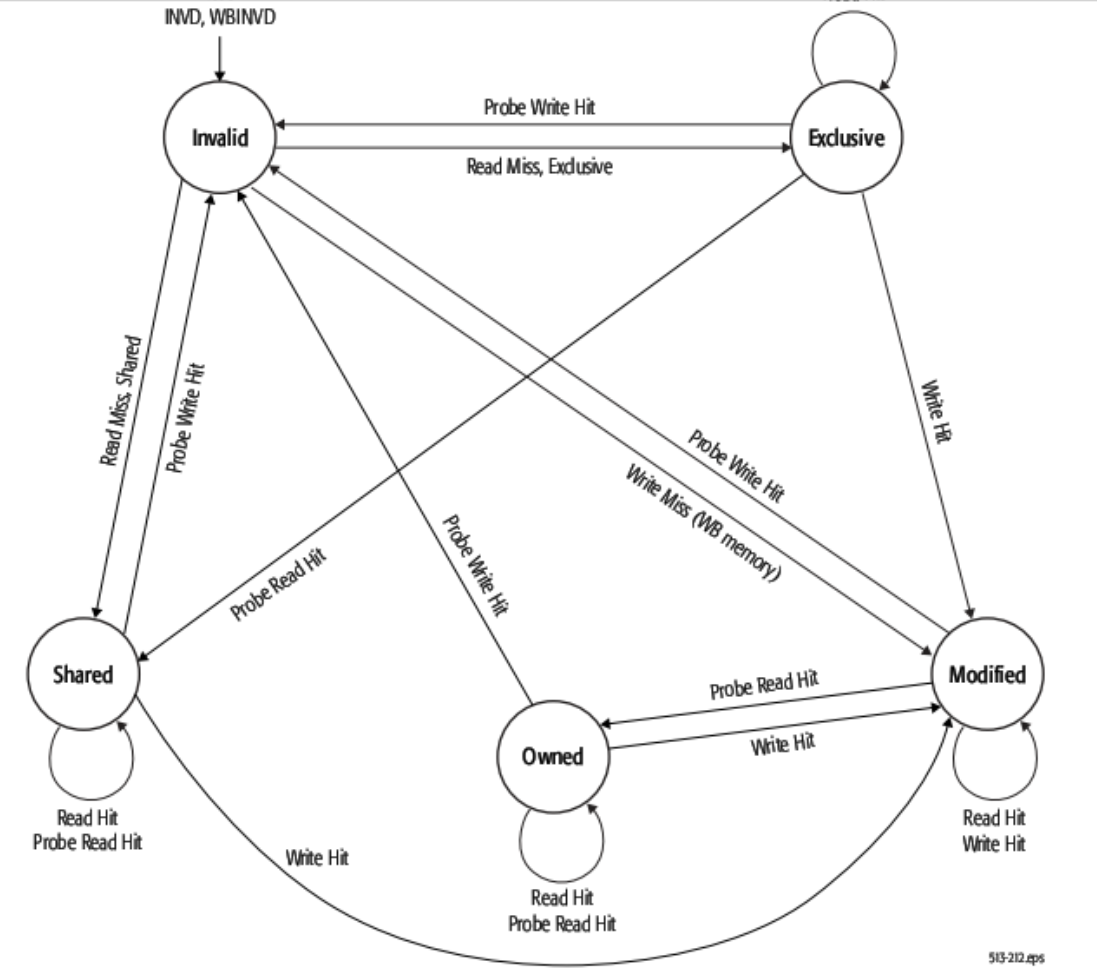
Cache States (MOESI) #
Caches can have 5 states in a SMM:
(M)odified: This processor changed the data in the cache and no other cache has a copy. (Main memory out of date). If the data gets evicted, then the entry needs to be flushed to main memory.
- Valid: 1; Dirty: 1, Shared: 0
(O)wner: Although the data in the cache is up-to-date, other caches may have a non-up-to-date Shared copy. So, if other caches need to access the data, they go to this cache rather than the main memory.
- Valid: 1, Dirty: 1, Shared: 1
(E)xclusive: The data in the cache is up-to-date, and this cache is the only one that has it. If any other cache reads this data, then it becomes shared. If it is written to, then the data becomes modified but does not need to be broadcast to other processors.
- Valid: 1, Dirty: 0, Shared: 0
(S)hared: The data in the cache is up-to-date, and other caches might also have a copy of it.
- Valid: 1, Dirty: 0, Shared: 1
(I)nvalid: The data is not in the cache.
Assembly Cache Instructions #
lr: Load Reserved: load an address, which puts it in the cache in some valid state (E,S,M,O).
sc: Store Conditional: properly handle storing into cache.
- If E or M: no extra behavior needed.
- If S or O: broadcast to other processors.
- If I: failure occurs.
Sharing and False Sharing #
A new type of cache miss: coherency miss. This occurs when data is shared between processors. If data is written to in a shared state, then all other caches must take a miss in the next cycle.
If two processors write to different parts of the same cache line (but not the same address), then false sharing occurs. One of the processors must necessarily take a cache miss.
One potential solution is CSP (Communicating Synchronous Processes) concurrency, which allows you to run multiple processes in a shared memory space. (Example: Golang)