ben's notes
ben's notesCongestion Control
If the capacity of the output link is less than the capacity of the incoming links, then it is possible for too many packets to arrive at once, overloading the link.
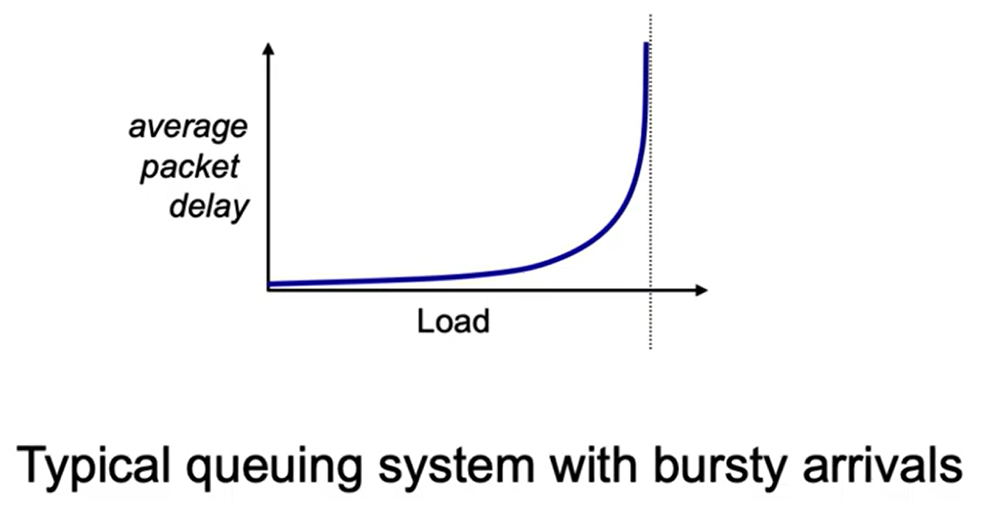
Here’s a graph of the packet delay as a function of load, assuming that we use a simple queue:
Fundamentally, congestion control is a resource allocation problem. However, it is very complex because changing one link can have a global impact, and these impacts need to be accounted for by every router on every flow change.
History (Karels and Jacobson) #
In the 1980s, the early internet experienced congestion collapse when the network was overloaded. As a solution, Van Jacobson and Michael Karels created an algorithm to adjust window size based on observed packet loss. This algorithm was quickly adopted because it required no router or application updates, only a small patch to BSD’s TCP implementation.
- 1986 congestion collapse: packets getting stuck in queues –> packets get dropped -> packets are resent -> more packets in network -> overload
Goals #
- Low packet delay and loss
- High link utilization
- Fair sharing across flows
These three goals are not always compatible, so we aim to strike a reasonable balance between them.
Possible Approaches #
- Reservations: use a system for flows to reserve bandwidth (see resource sharing (packet and circuit switching)). However, this comes with all of the issues of reservations, which was not used for general internet architecture.
- Pricing Model: treat bandwidth as a scarce commodity, and raise the costs of links in high demand so new flows go elsewhere. In many cases, this model is optimal but requires a payment framework (which doesn’t exist outside of datacenters).
- Dynamic Adjustment: hosts dynamically learn the current level of congestion and adjust sending rate accordingly. This is a highly general solution that doesn’t assume anything about the business model or application requirements. However, it assumes that clients are honest about their calculations, and that there are few malicious actors.
- Host-based congestion control: no support from routers; hosts individually adjust rate based on implicit feedback (packet delay, acks, dropped packets)
- Router-assisted congestion control: routers signal congestion back to hosts, and hosts pick rate based on explicit feedback
Detecting Congestion #
Packet loss: if packets are dropped, congestion probably occurred so send less
- Pro: Fail-safe signal since TCP already implements reliability
- Con: doesn’t account for non-congestive loss like checksum errors; can be confused with packet reordering due to TCP using cumulative ACKs
Increase in packet delay: congestion may be correlated with packet delay
- Historically not used due to complications in measuring delay
- Used by Google’s BBR protocol
Implementation #
Discovering an Initial Rate #
Goal: Estimate available bandwidth in a safe and efficient manner. Solution: Slow Start
- Start at a very small rate
- Increase exponentially until first loss (double rate)
- First safe rate is half of the rate where first loss was experienced
- double CWND every RTT
Rate Adjustment #
After the initial rate is determined using Slow Start, TCP needs to dynamically adjust the rate to adapt to changes in available bandwidth.
There is a tradeoff between efficiency (utilization of total available bandwidth) and fairness (how similar the allocations are for different flows). We can model this tradeoff using this graph:
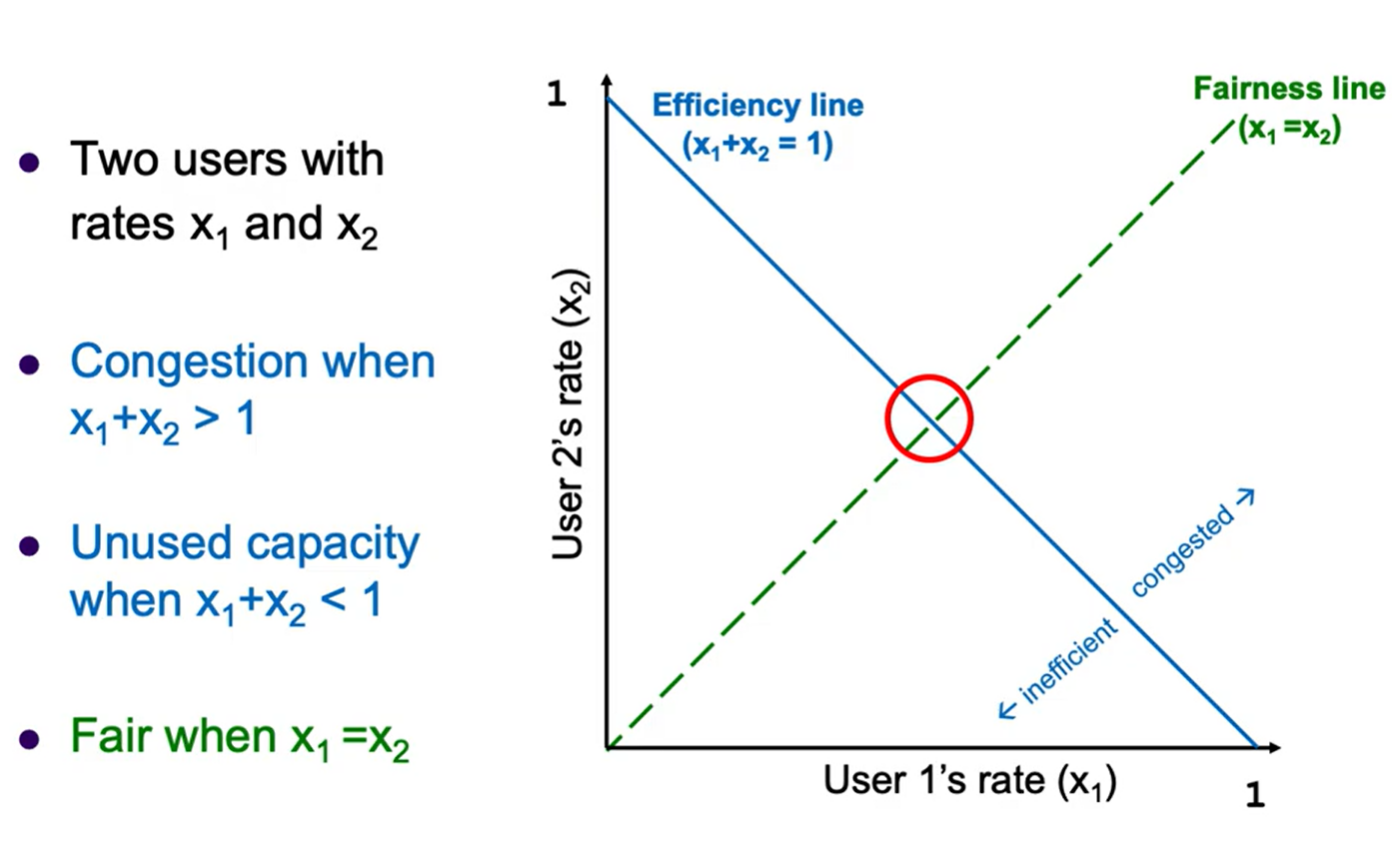
- The goal is to get as close to the center as possible (both on the efficiency and fairness lines).
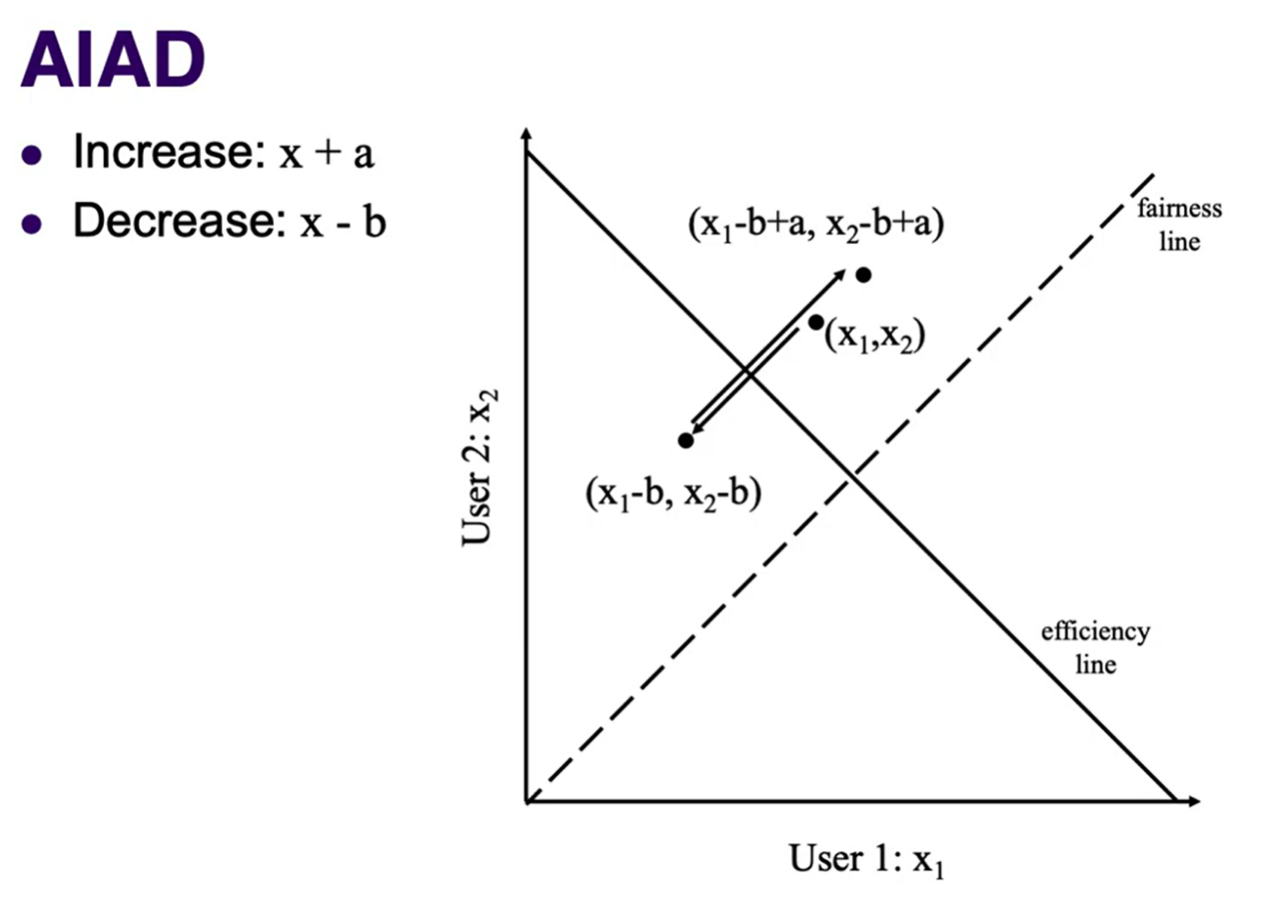
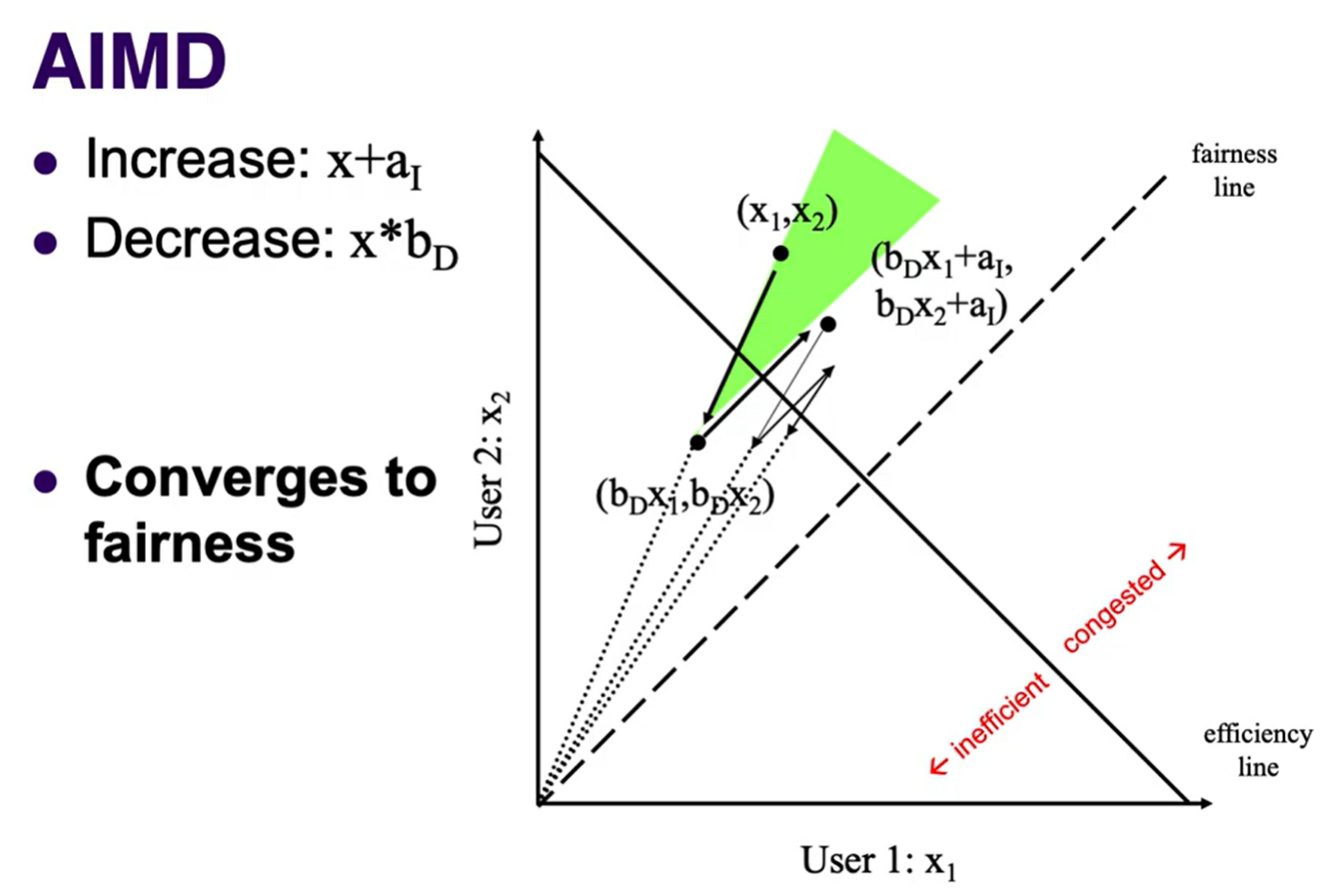
There are 4 methods of changing the rate. A = additive, M = multiplicative, I = increase, D = decrease.
- AIAD: can become more efficient, but will never converge to fairness since the slope of the line never changes
- MIMD: similarly to AIAD, can be more efficient but doesn’t converge to fairness.
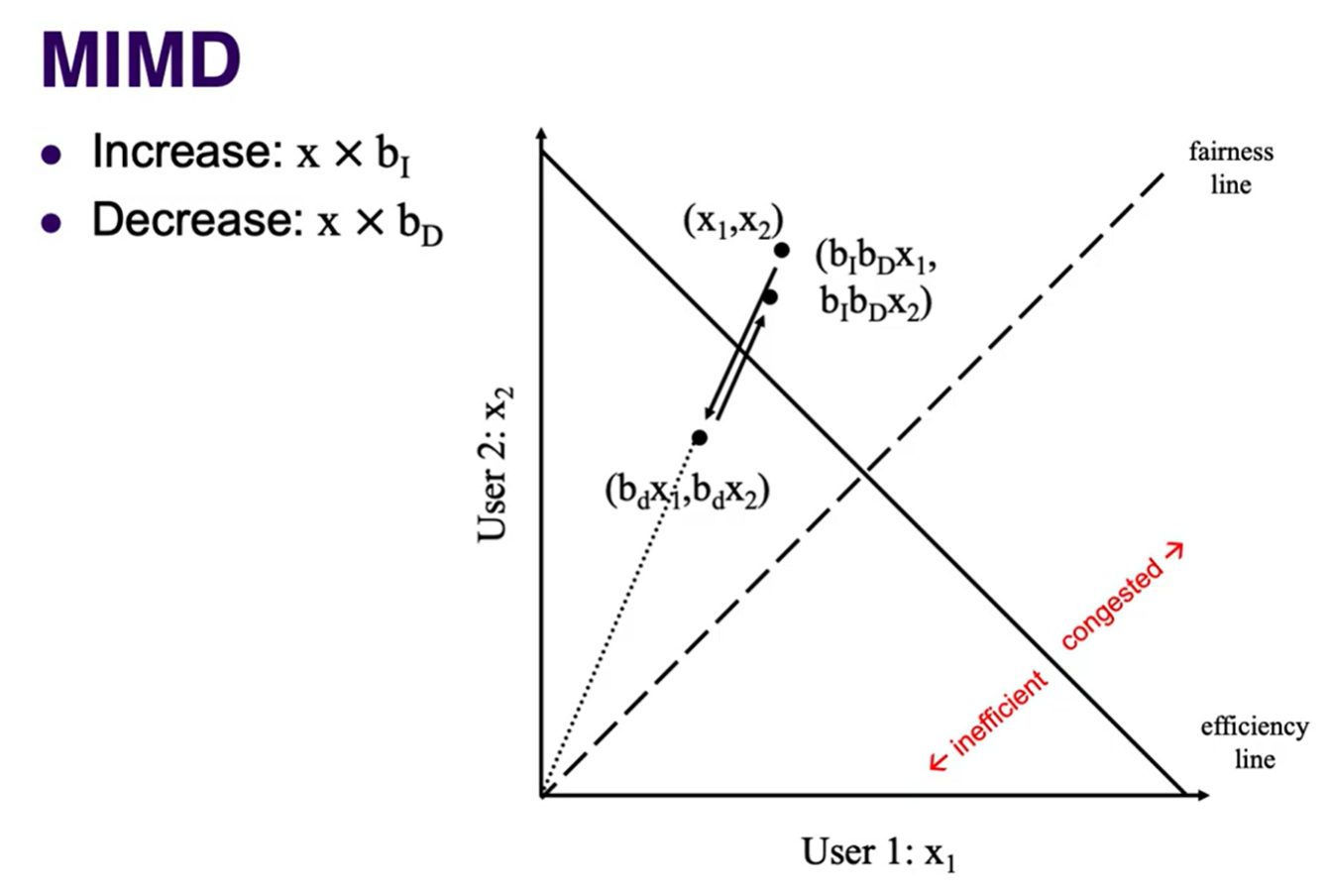
- Slope of the line is always $x_2/x_1$
- MIAD: maximally unfair; will allocate all of the capacity to one flow (converge to either X or Y axis)
- AIMD: both efficient and fair