 ben's notes
ben's notesTries
Main Ideas #
A trie is a specific implementation of a set and is short for retrieval tree.
It only works on sets with a finite alphabet, like digits or ASCII characters, for example. The idea is that each node can act like an array containing all characters in the alphabet and we can just access the branches super fast by indexing into them!
Tries are fantastic for searching to see if a word is contained in a set. Here’s an example:
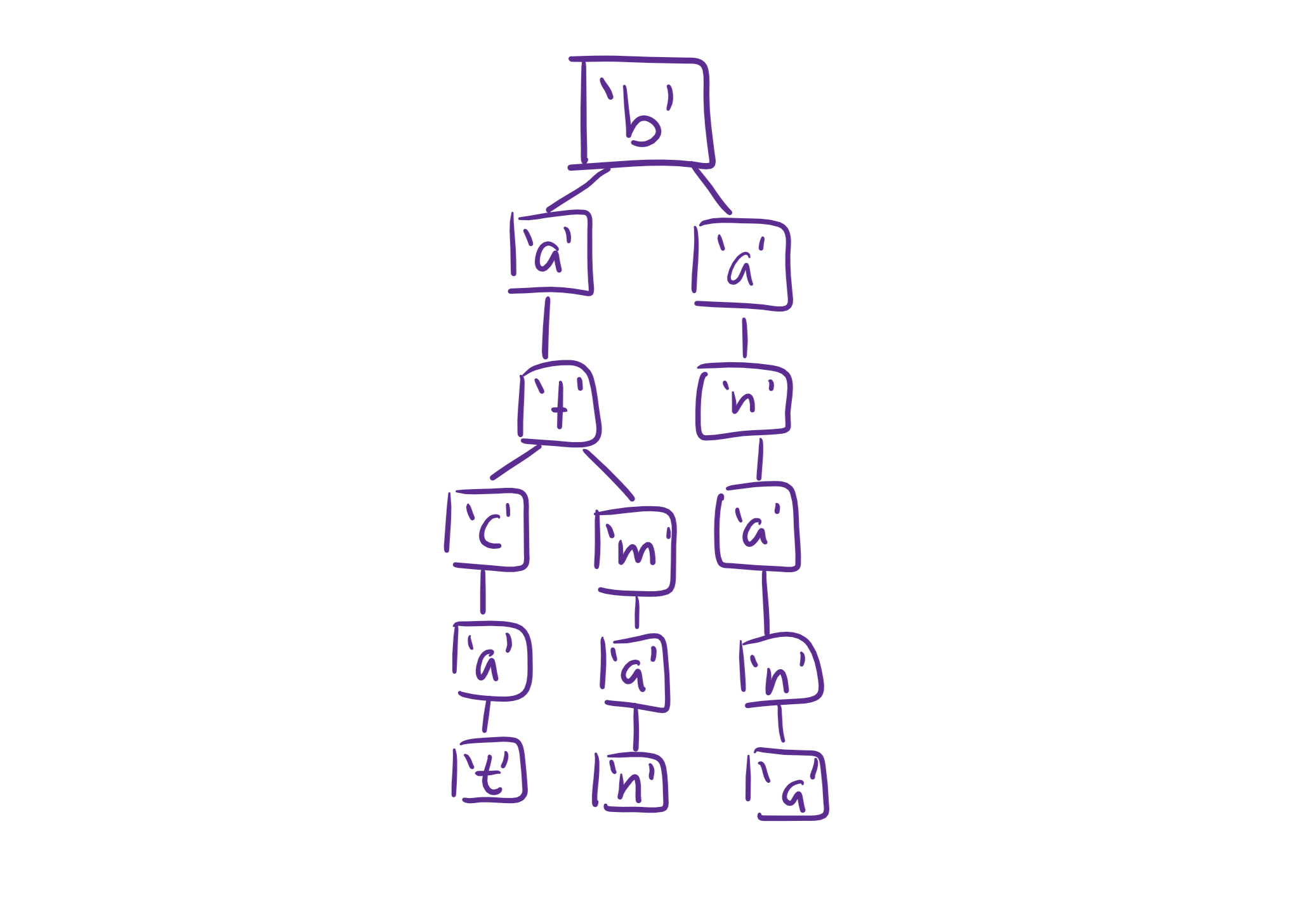
This is great because it makes the add() and contains() functions run in $\Theta(1)$ time! Additionally, it makes special string operations like prefix matching or autocomplete very efficient.
We can improve this data structure a lot- for instance, we can condense the leaves to reduce the number of nodes like this:
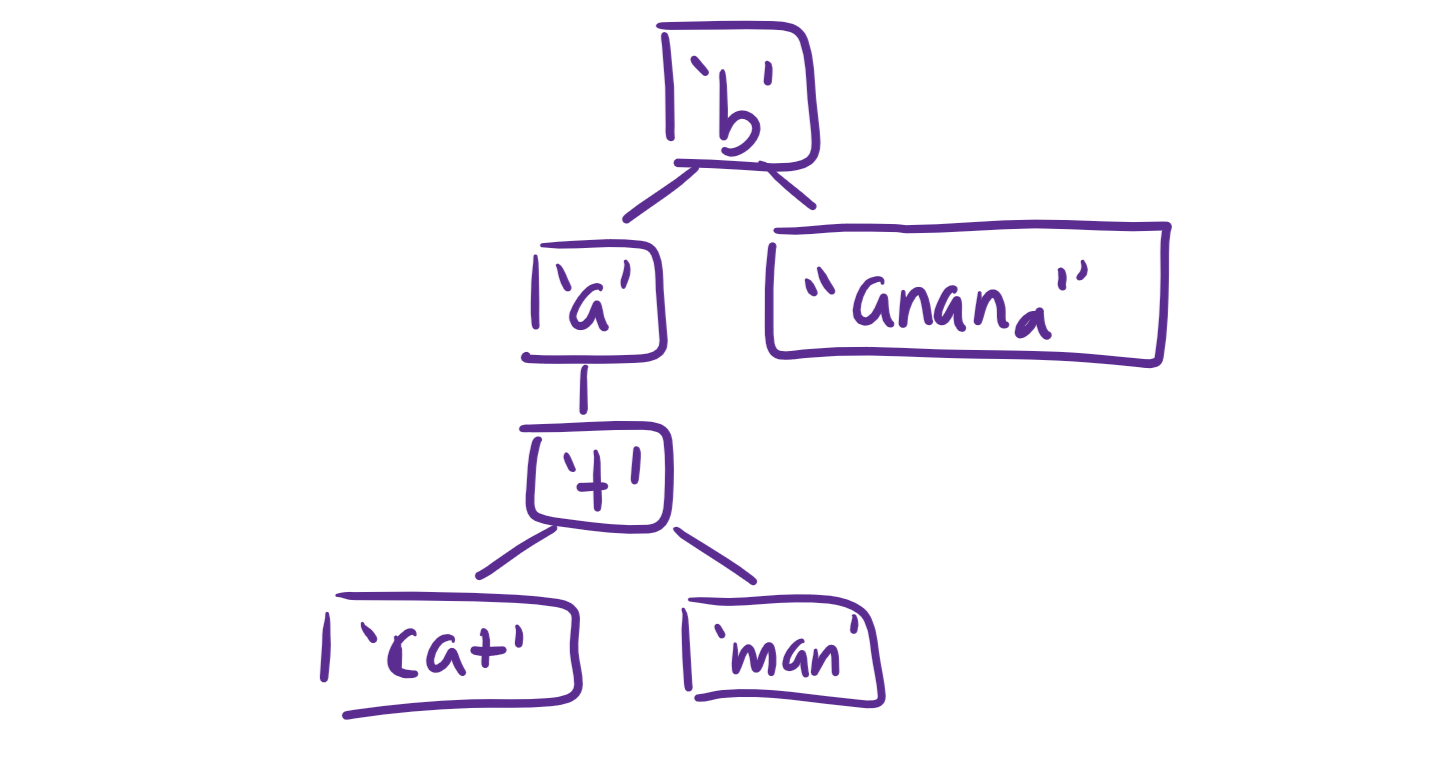
I won’t go into too much detail on how to optimize it further, or how to implement the actual functions efficiently, but hopefully you’ll have a good sense of how to do it yourself after learning about concepts like Hashing and Hash Tables or Sets etc.